Common Extract and Load Scenarios
The most common extract and load scenarios are as follows.
Single Extract and Single Load Scenario
Multiple Extract and Single Load Scenario
Multiple Extract and Multiple Load Scenario
The multiple extract scenarios apply to both homogeneous and
heterogeneous
multi-source execution plan types.
Single Extract and Single Load Scenario
In the single extract and single load scenario, as shown in Figure 9–3, data is extracted from a
single source, loaded into staging tables, and then loaded into the data warehouse.
Figure 9–3
Single Extract and Single Load Option
Truncate
Table Behavior in a Single Extract Scenario
When DAC
truncates a table, as part of the truncation process, it also drops and recreates
indexes (if the table has indexes) and analyzes the table after the truncation.
In a
single extract scenario, the truncation process for a table without indexes is
as follows:
1.
Truncate table.
2. Run Informatica mapping
3. Analyze table Table.
For a table with indexes, the truncation process is as follows:
1. Truncate table.
2. Drop indexes.
3. Run Informatica mapping.
4. Recreate indexes.
5. Analyze Table.
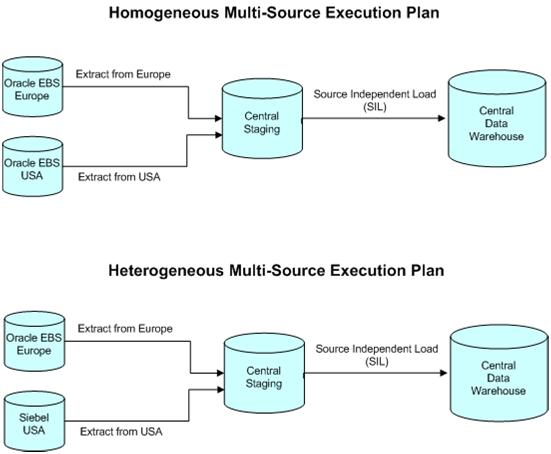
Multiple Extract and Single Load Scenario
In the multiple extract and single load scenario, as shown in Figure 9–4, data is extracted from
multiple sources and loaded into central staging tables.
You can stagger the extracts to accommodate different time zones
by setting the Delay property found in the Parameters subtab of the Execution
Plans tab in the Execute view.
After all of the extract tasks have completed, the data is loaded
into the data
warehouse in a single load process.
Figure 9–4
Multiple Extract and Single Load Option
Truncate
Table Behavior in a Multiple Extract Scenario
1)
When DAC truncates a table, as part of the truncation process,
it also drops and recreates indexes (if the table has indexes) and analyzes the
table after the truncation.
2)
If a target table is shared across different sources, it will
be truncated only once.
3)
The priority of the data source determines which of the
extracts truncates the tables.
4)
The task reading from the data source with the highest priority
truncates the tables and drops the indices.
5)
The last
task writing to the table from the data source with the highest priority
creates the indexes.
In a multiple extract scenario, the truncation process for a table
without indexes is as follows:
1. Truncate table (first extract task).
2. Run Informatica mapping (first extract task).
3. Run Informatica mapping (second extract task).
4. Analyze table.
For a table with indexes, the truncation process is as follows:
1. Truncate table (first extract task).
2. Drop indexes (first extract task).
3. Run Informatica mapping (first extract task).
4. Run Informatica mapping (second extract task).
5. Recreate indexes (second extract task).
6. Analyze table.
Multiple Extract and Multiple Load Scenario
Figure 9–5 shows a multiple extract and
multiple load scenario.
Figure 9–5
Multiple Extract and Multiple Load Scenario







No comments:
Post a Comment